AbstractQueuedSynchronizer
2014-10-20
AbstractQueuedSynchronizer
如果不读源码,我不会知道AbstractQueuedSynchronizer,更不会认识到它使整个java.util.concurrent包中众多并发工具类的灵魂。AbstractQueuedSynchronizer官方的推荐用法是,在并发工具类内部使用一个同步器sync实现来继承AbstractQueuedSynchronizer,并把预留的抽象方法(例如acquire和release)赋予业务含义后,同步相关的操作就交由sync来执行了。
查看源码可以看到,AbstractQueuedSynchronizer提供了一个基于FIFO队列,FIFO队列使用的是链表的数据结构,其中的每一个node都拥有自身的可改变的状态waitStatus,而node自身又可以获得他的前驱node和后继node,每个node封装了当前所在线程.AbstractQueuedSynchronizer会通过响应不同的方法,根据node不同的waitStatus,达到操作线程的目的.
我认为首先需要明确的是node的waitStatus:
waitStatus:
- 1.CANCELLED. 表示当前节点由于超时或终端而需要被取消
- -1.SIGNAL.表示当前节点的后继节点包含的线程需要被唤醒
- -2.CONDITION.表示当前节点在等待condition,也就是在condition队列中
- -3.PROPAGATE.只有在队列头会被设置,表示releaseShared需要被传播给后续节点。
- 0.不属于上述的任何一种。用来表示正常处于同步状态的node,初始化时会被设置为0.
用数字标示纯粹是为了运算方便。负数用来表示当前节点不需要被唤醒。
每个node还有一个类型属性:共享(shared)或独占(exclusive)。通常不会同时出现在FIFO队列中,不过ReadWriteLock是一个列外。共享模式指的是允许多个线程获取同一个锁而且可能获取成功,独占模式指的是一个锁如果被一个线程持有,其他线程必须等待。多个线程读取一个文件可以采用共享模式,而当有一个线程在写文件时不会允许另一个线程写这个文件,这就是独占模式的应用场景。
整理完这些基础知识之后,在这里先拿闭锁CountDownLatch举个例子,因为闭锁相对来说最常见,用法也最单一。因此它的实现也比较简单。(我非常希望能在这篇笔记中把所有涉及到AbstractQueuedSynchronizer的并发工具都研究一遍。)
CountDownLatch
闭锁CountDownLatch的用法实在太简单了。在这里给个小例子:
class Driver { // ...
void main() throws InterruptedException {
CountDownLatch startSignal = new CountDownLatch(1);
CountDownLatch doneSignal = new CountDownLatch(N);
for (int i = 0; i < N; ++i) // create and start threads
new Thread(new Worker(startSignal, doneSignal)).start();
doSomethingElse(); // don't let run yet
startSignal.countDown(); // let all threads proceed
doSomethingElse();
doneSignal.await(); // wait for all to finish
}
}
class Worker implements Runnable {
private final CountDownLatch startSignal;
private final CountDownLatch doneSignal;
Worker(CountDownLatch startSignal, CountDownLatch doneSignal) {
this.startSignal = startSignal;
this.doneSignal = doneSignal;
}
public void run() {
try {
startSignal.await();
doWork();
doneSignal.countDown();
} catch (InterruptedException ex) {
} // return;
}
void doWork() {...}
}
之后来看看CountDownLatch内部都做了哪些工作。唯一的构造方法是传入一个count值,初始化count为多少,就代表这个闭锁可以countDown多少次。
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
在构造函数中创建了一个同步器Sync。这个sync继承了AbstractQueuedSynchronizer,并完成了CountDownLatch的所有工作。
private static final class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 4982264981922014374L;
Sync(int count) {
setState(count);
}
int getCount() {
return getState();
}
protected int tryAcquireShared(int acquires) {
return getState() == 0? 1 : -1;
}
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
for (;;) {
int c = getState();
if (c == 0)
return false;
int nextc = c-1;
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
}
从源码中可以看到由CountDownLatch的构造函数传入的count被设置为sync的state,state在AbstractQueuedSynchronizer内部是volatile修饰的,它的状态改变对所有线程可见。
AbstractQueuedSynchronizer会强制他的子类实现tryAcquire(或tryAcquireShared),tryRelease(或tryReleaseShared)方法,从名称上可以看出,分别代表独占式和共享式.在这里CountDownLatch的Sync是共享式的同步器。
先看一下CountDownLatch的await方法是如何实现的。当某个线程CountDownLatch调用await方法时,会在这里阻塞,等待CountDownLatch调用countDown方法的次数超过count值,才被唤醒。
public void await() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
public final void acquireSharedInterruptibly(int arg) throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
acquireSharedInterruptibly方法是在AbstractQueuedSynchronizer已经实现好的。首先他会检查当前线程是否已经被中断,然后调用用户自行实现的tryAcquireShared方法检查是否满足状态,tryAcquireShared方法的返回值为int类型。方法规定:
返回值
- 大于0.表示本次尝试获取锁成功,并且后续的其他线程再次尝试获取锁仍然有可能成功(后续的其他线程需要去检查是否能获取锁)
- 等于0.表示本次尝试成功,但后续的其他线程不会成功获取锁
- 小于0.表示本次尝试失败.
再来看一下CountDownLatch实现的tryAcquireShared方法体:
public int tryAcquireShared(int acquires) {
return getState() == 0? 1 : -1;
}
可以看到只有getState(),也就是构造函数中的count值为0时,才会返回1,即能够获取锁,并且后续的其他线程再次尝试获取锁仍然有可能成功。反之,则失败。
当CountDownLatch从未countDown过,自然在await时会失败,继而调用doAcquireSharedInterruptibly方法。
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);//把自己设置为head节点并唤醒后继节点
p.next = null; // help GC
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
认真分析一下这个方法.
- 首先创建共享类型的node并加入到FIFO队列中
- 获取node的前驱节点p
- 如果前驱节点p为head节点,即当前节点很有可能能获得锁,则再次尝试获取锁tryAcquireShared
- 如果获取锁成功,则执行setHeadAndPropagate,用来把当前node设置为head结点,并向后传播自己获取锁成功的信息.
- 如果前驱节点p不是head节点,或者p虽然是head节点,但当前节点没有成功获得锁。则检查是否需要让线程等待(park),如果需要,则进入等待状态。
- 在当前线程被唤醒后,查看是否是因为中断而被唤醒的。如果是因为中断被唤醒的,直接中断,并在finally中取消这次获取锁的操作(cancelAcquire),即从队列中删除当前节点,并顺便从队列中剔除已经cancel的节点,如果需要,唤醒当前节点的后继节点。
再来看看addWaiter方法:
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
上面两个方法可以合在一起看
- addWaiter时首先迅速判断一下队列是不是已经建立好了,即tail节点是不是已经存在了,如果存在,则把当前节点加到队列末尾。
- 如果不存在,则进入enq方法,double check一下,确定队列仍然没有创建,则通过cas的原子方法创建队列。
我还是觉得非常有必要再看一眼shouldParkAfterFailedAcquire方法,这个方法也是我最疑惑的一点。
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
/*
* This node has already set status asking a release
* to signal it, so it can safely park.
*/
return true;
if (ws > 0) {
/*
* Predecessor was cancelled. Skip over predecessors and
* indicate retry.
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
/*
* waitStatus must be 0 or PROPAGATE. Indicate that we
* need a signal, but don't park yet. Caller will need to
* retry to make sure it cannot acquire before parking.
*/
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
因为我很疑惑,所以在这里写下的东西只是我的理解。这个方法总共有几个判断条件。
- 如果前驱节点的状态是SIGNAL,则返回true,也就是让当前节点立刻休眠。
- 如果前驱结点被取消,则尝试在队列中向前查找,找到一个没有被取消的节点,与当前节点关联上。这意味着在这里也会从队列中删除掉所有的CANCEL状态的节点。这个动作实际上发生在很多地方,因为设置节点的CANCEL状态和删除CANCEL并不是串行的。
- 如果前驱结点状态为SYNC或PROPAGATE,则设置它的状态为SIGNAL,并返回false,即当前节点先不休眠,尝试自旋一次后再次进行获取锁的操作。
到此为止CountDownLatch.await方法就都解析完了。再来看看当执行CountDownLatch.countDown时,同步器都做了些什么。
public void countDown() {
sync.releaseShared(1);
}
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
可以看到countDown方法实际上执行的是AbstractQueuedSynchronizer中的releaseShared方法,从方法名上得知也是共享模式下专用的方法。首先会去验证一下能否释放锁,tryReleaseShared是在CountDownLatch的同步器中实现的,在这里可以再回顾一下。用自旋和cas保证设置把count值--的原子性,当count=0时直接返回false。
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
for (;;) {
int c = getState();
if (c == 0)
return false;
int nextc = c-1;
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
尝试获得锁成功之后需要执行doReleaseShared做之后的处理。
private void doReleaseShared() {
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}
这个方法有以下几个步骤:
- 首先获得head node,检查head node不为空且不是最后一个节点时,会检查head node的状态,如果是SIGNAL,则用cas设为SYNC,成功后唤醒后继节点。
- 如果碰巧其他线程已经提前吧head node设置为SYNC状态,则再次把其状态设为PROPAGATE,用来能够继续向后传播。
- 当head node没有被改变时,方法执行完毕。
这个方法因为唤醒了其他线程,所以会造成连锁反应。这里用张图来表示或许会更清晰一下。
当有两个线程都先后尝试获取锁,之后countDown方法被执行,count归零后,两个线程依次被唤醒的FIFO队列的快照和node状态如图所示:
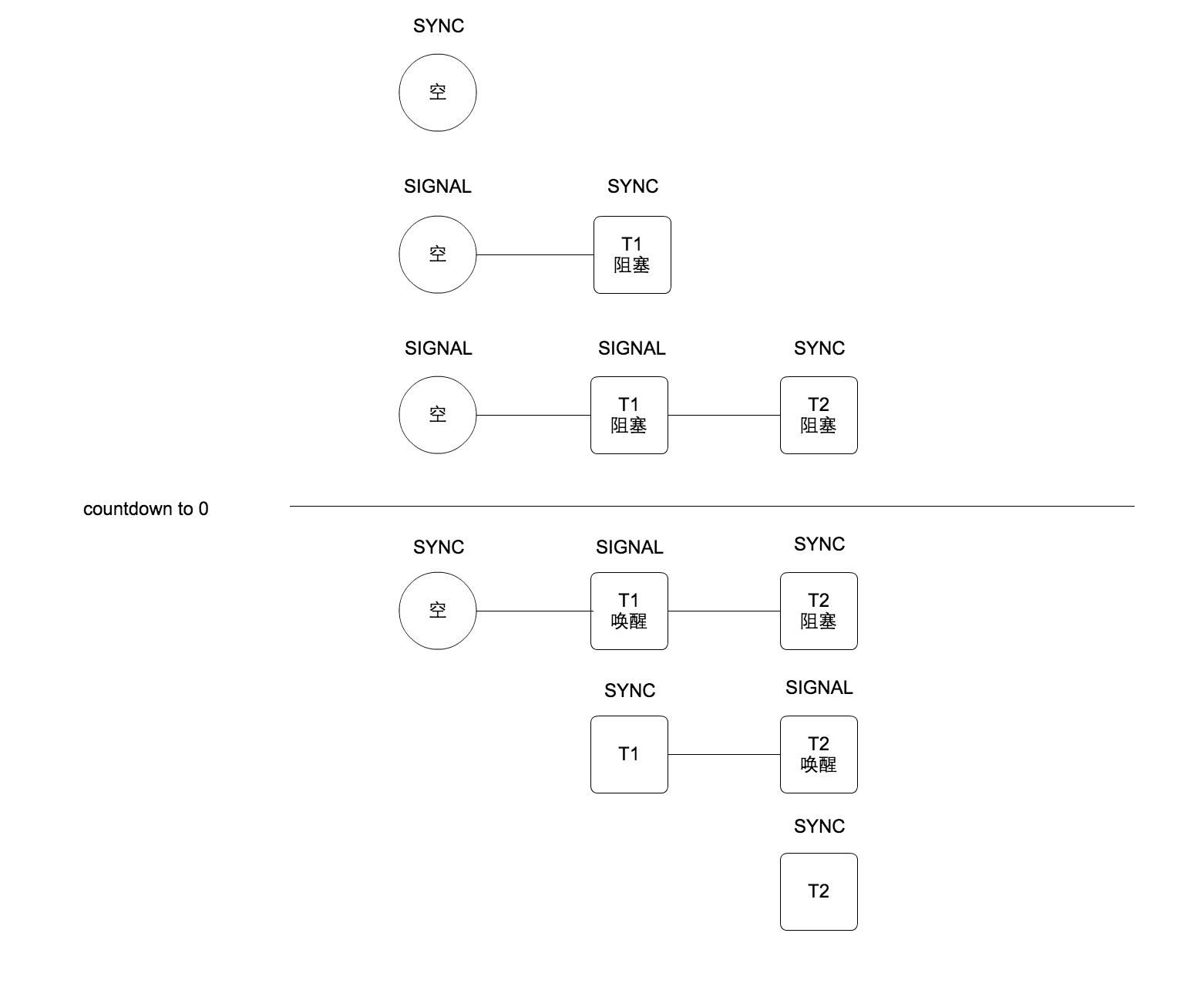
可以看到第一个线程T1尝试获取锁失败时,会初始化这个队列,创建一个空node, 这个node不包含任何线程,纯粹为了占位用,作为head node。并把head node的状态从SYNC切换到SIGNAL,自身维持SYNC的状态,并阻塞。当第二个线程T2,尝试获取锁失败时,会把他的前驱node T1的状态从SYNC切换到SIGNAL,自身维持SYNC的状态,并阻塞。
经过countDown,也就是调用releaseShared方法后。检查当前head node,发现是空节点,状态为SIGNAL,把空节点的状态还原为SYNC,唤醒自己的后继node T1。node T1被唤醒后,进入自旋,尝试获得锁,因为count=0,则成功获得锁,继而调用setHeadAndPropagate方法,把自己设置为head node,并尝试向后传播。因为后集结点的类型也是共享类型,会再次触发doReleaseShared方法。这回因为T1已经是head node,发现T1状态为SIGNAL,便把自己的状态还原为SYNC,并唤醒自己的后继node T2。T2被唤醒后自旋……
所以在等待中的各个node会依次被唤醒。在执行unparkSuccessor方法唤醒后继节点的时候还会把队列中状态为CANCELLED的node移除队列。
java.util.concurrent中的并发工具类最显著的特点就是提供了在一定时间内尝试获取锁超时返回的特性。CountDownLatch也不例外。
public boolean await(long timeout, TimeUnit unit)
throws InterruptedException {
return sync.tryAcquireSharedNanos(1, unit.toNanos(timeout));
}
public final boolean tryAcquireSharedNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
return tryAcquireShared(arg) >= 0 ||
doAcquireSharedNanos(arg, nanosTimeout);
}
await方法提供加入超时时间的重载,用途是等待一段时间,如果count没有减为0则返回。这个方法调用的是AbstractQueuedSynchronizer中的tryAcquireSharedNanos方法,第二个参数为超时时间。外部的所有逻辑与不带超时时间的方法几乎一致。重点在于doAcquireSharedNanos中加入了第二个维度,时间维度。
private boolean doAcquireSharedNanos(int arg, long nanosTimeout)
throws InterruptedException {
long lastTime = System.nanoTime();
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
failed = false;
return true;
}
}
if (nanosTimeout <= 0)
return false;
if (shouldParkAfterFailedAcquire(p, node) &&
nanosTimeout > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
long now = System.nanoTime();
nanosTimeout -= now - lastTime;
lastTime = now;
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
这个方法不同之处用两点。首先引入了自旋锁的概念,如果超时时间很短,则不让线程挂起,而是通过自旋代替,这样线程获得锁很快就释放的情况下能消耗少量的cpu资源节省线程挂起和恢复的性能损耗。
当然如果超时时间大于一个阈值(spinForTimeoutThreshold),会使用LockSupport.parkNanos(this, nanosTimeout)把线程在一定时间内阻塞。
其他所有逻辑和不带超时时间的方法一致。
ReentrantLock
可重入锁ReentrantLock是典型的独占式的同步器,可以用来代替synchronized关键字,而且还提供更加丰富的功能。
首先从构造函数入手:
public ReentrantLock() {
sync = new NonfairSync();
}
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
默认的构造函数创建的是非公平锁,对于想要获取锁并处于阻塞状态的线程们来说,并不是等待时间最长的线程,即排在队列前面的线程先获得锁。而公平锁相反,能保证等待时间最长的线程,即排在队列前面的线程先获得锁。
不如同时分析非公平锁NonfairSync和公平锁FairSync的实现原理吧,这样可以有个对比,能看的出差别到底在哪。
首先来看获取锁的操作:
public void lock() {
sync.lock();
}
非公平锁:
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
公平锁:
final void lock() {
acquire(1);
}
NonfairSync,第一时间尝试用cas设置state状态,如果成功,会设置当前线程为占有锁的线程。如果不成功,会常规的调用acquire方法。
FairSync,直接调用acquire方法。
再详细看看acquire方法,这个方法是在AbstractQueuedSynchronizer中已经实现好的
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
这里会首先通过tryAcquire方法尝试获取锁,接下来看tryAcquire在NonfairSync和FairSync中的具体实现:
非公平锁:
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
公平锁:
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
这两个方法几乎不用多说,逻辑清晰,区别就在于公平锁在获取锁之前要判断一下,当前线程是不是排在队列最前面,即等待时间最长的线程,如果是,才能获得锁。
再仔细看一下如何判断自己是不是队列中最前面的线程:
public final boolean hasQueuedPredecessors() {
// The correctness of this depends on head being initialized
// before tail and on head.next being accurate if the current
// thread is first in queue.
Node t = tail; // Read fields in reverse initialization order
Node h = head;
Node s;
return h != t &&
((s = h.next) == null || s.thread != Thread.currentThread());
}
我们知道AbstractQueuedSynchronizer的队列在排队时默认的head节点是空节点,而已经获得锁的节点会被设为head节点,所以想要获得锁的节点永远只会从head节点的后继节点开始排起。所以判断条件就是,如果队列中有节点(h != t),并且head节点的后继节点是空或后继节点不是当前线程的所在节点((s = h.next) == null || s.thread != Thread.currentThread()),则当前线程之前仍然有前驱节点,所以无法获得锁。
如果没能获得锁则需要创建node,并排入队列中。
acquireQueued(addWaiter(Node.EXCLUSIVE), arg)
addWaiter方法就不多说了,上文详细分析过。这里主要看看acquireQueued方法。
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
是不是很熟悉?这个方法与获取共享锁唯一的区别就是,当获取锁成功之后把当前节点设置为head节点,但不会向后传播,毕竟只有共享锁才会被多个线程同时获得锁,独占锁顾名思义,是某一个线程专属的。
这之后,我们都知道synchronized的锁无法被中断,自然而然ReentrantLock也就提供了可中断的锁的实现。
ReentrantLock中:
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
AbstractQueuedSynchronizer中:
public final void acquireInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
private void doAcquireInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
带中断的lock方法归根结底就是在parkAndCheckInterrupt方法中如果检查到当前线程已经被中断,会再次抛出InterruptedException异常而已。
ReentrantLock还提供了tryLock方法,用于尝试获得锁。不过注意!!!这个方法调用的是sync.nonfairTryAcquire方法,回忆一下之前的源代码,就会发现调用这个方法会造成,如果可以获得锁,就会立即获得,即便初始化的是公平锁!这个方法会打破公平性,另外需要注意的是,tryLock之后也需要在finally中调用unlock方法。
public boolean tryLock() {
return sync.nonfairTryAcquire(1);
}
最后,来看一下带超时时间的锁获取方法:
ReentrantLock中:
public boolean tryLock(long timeout, TimeUnit unit)
throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(timeout));
}
AbstractQueuedSynchronizer中:
public final boolean tryAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
return tryAcquire(arg) ||
doAcquireNanos(arg, nanosTimeout);
}
private boolean doAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
long lastTime = System.nanoTime();
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return true;
}
if (nanosTimeout <= 0)
return false;
if (shouldParkAfterFailedAcquire(p, node) &&
nanosTimeout > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
long now = System.nanoTime();
nanosTimeout -= now - lastTime;
lastTime = now;
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
写到这里,我觉得也有必要提一下为什么要把AbstractQueuedSynchronizer的实现类都写在一篇笔记里的原因了。共享模式和独占模式代码上的区别简直太小了,但是可重用度并不高,毕竟性能至上。
加锁的所有方法,也就这些了。下面来看看如何解锁:
ReentrantLock中:
public void unlock() {
sync.release(1);
}
ReentrantLock-sync中:
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
AbstractQueuedSynchronizer中:
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
独占模式的unlock方法比共享模式简单许多,tryRelease判断条件就是如果自己没加锁缺想解锁,这不搞笑吗?直接异常抛出。接下来判断自己占用了几层锁,如果解到最后一层后才宣布锁被我释放了。之后会通知后继节点。对比共享模式的通知所有等待的节点,独占模式只对当前节点的后继节点有通知的义务。
接下来是一些简单的工具方法的介绍:
- getHoldCount.用来返回锁被获取了多少层,当然只有自己是获取锁的线程时才能知道,否则对其他线程来说都是0层。
- isHeldByCurrentThread.询问是不是当前线程获得的锁
- isLocked.锁是不是已经被获取了
- isFair.是不是公平锁
- getOwner.哪个线程获得了锁,返回的是线程对象
- hasQueuedThreads.有没有线程在排队,判断条件是head == tail
- hasQueuedThread(Thread thread).这个线程是不是在排队
- getQueueLength.队列的长度
- getQueuedThreads.返回所有排队线程的集合
就这些!
Condition
Condition在我眼中一直是很神秘的,这源于Object.wait方法,大家都知道Condition.await方法可以取代它,其实早在使用Object.wait和notify的时候我就不太明白,为什么这个看上去和synchronized无任何关系的方法必须要写在同步代码块里,否则就会抛异常。
仔细查看了Condition源码之后,我彻底明白了其中的原理。
先举一个jdk在注释中给出的例子:
class BoundedBuffer {
final Lock lock = new ReentrantLock();
final Condition notFull = lock.newCondition();
final Condition notEmpty = lock.newCondition();
final Object[] items = new Object[100];
int putptr, takeptr, count;
public void put(Object x) throws InterruptedException {
lock.lock();
try {
while (count == items.length)
notFull.await();
items[putptr] = x;
if (++putptr == items.length) putptr = 0;
++count;
notEmpty.signal();
} finally {
lock.unlock();
}
}
public Object take() throws InterruptedException {
lock.lock();
try {
while (count == 0)
notEmpty.await();
Object x = items[takeptr];
if (++takeptr == items.length) takeptr = 0;
--count;
notFull.signal();
return x;
} finally {
lock.unlock();
}
}
}
上面的代码中初始化了一个ReentrantLock lock,和两个Condition notFull和notEmpty,模拟了一个BlockArrayQueue的容器,put和take在容器满和容器空得情况下分别阻塞。Condition需要配合lock使用,在锁内,可以让某个Condition await, 也可以让某个Condition signal。这相当于Object的wait和notify,与wait和notify相仿,当Condition在锁内await的时候会释放当前持有的锁,知道被中断或其他线程调用同一个Condition的signal方法。
Condition实际上是一个接口,他描述了Condition的实现类的所有行为,而实现类ConditionObject是AbstractQueuedSynchronizer的一个内部类,这很重要,因为ConditionObject需要调用AbstractQueuedSynchronizer定义的方法。 因为Lock接口本身需要实现newCondition方法,不同的Lock的实现类(比如jdk本身提供的ReentrantLock,WriteLock)虽然都会实现这个方法,而且实质都是new ConditionObject(),但Condition的行为会随着Lock的实现类有所不同。下面会拿ReentrantLock举例。
public class ConditionObject implements Condition, java.io.Serializable {
private transient Node firstWaiter;
private transient Node lastWaiter;
}
ConditionObject自带两个属性firstWaiter,lastWaiter用来表示Condition队列的头尾元素。当有多个线程都在await中,等待signal时,必须有FIFO队列才能保证先await的线程可以被最先signal。
先来看await方法:
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
代码没几行,不过对我来说理解起来还是花了些时间的。
首先这个方法可以响应中断,这与Object.wait方法一样。所以方法调用之初会判断当前线程的中断状态,如果已经中断,则直接抛出InterruptedException。
接下来addConditionWaiter方法会把当前线程放入Condition队列中。
private Node addConditionWaiter() {
Node t = lastWaiter;
// If lastWaiter is cancelled, clean out.
if (t != null && t.waitStatus != Node.CONDITION) {
unlinkCancelledWaiters();
t = lastWaiter;
}
Node node = new Node(Thread.currentThread(), Node.CONDITION);
if (t == null)
firstWaiter = node;
else
t.nextWaiter = node;
lastWaiter = node;
return node;
}
当Condition队列的队尾节点lastWaiter已经被取消的话,会调用unlinkCancelledWaiters方法,这个方法会从队列头开始检查,去除掉队列中的所有已取消的节点。之后把包含当前线程的节点放入队列中。
再回头看看await方法,当前节点放入Condition队列后,会执行fullyRelease(node)方法,并返回当前保存的state值。为什么要在这里执行fullyRelease,其实是以为如果当前线程在锁内想要await,必须释放锁的缘故。而且他必须能够释放锁,否则会抛出IllegalMonitorStateException异常。这就是在锁外执行await的结果。
final int fullyRelease(Node node) {
boolean failed = true;
try {
int savedState = getState();
if (release(savedState)) {
failed = false;
return savedState;
} else {
throw new IllegalMonitorStateException();
}
} finally {
if (failed)
node.waitStatus = Node.CANCELLED;
}
}
值得注意的是,如果释放锁失败了,会主动把当前节点的状态置为Node.CANCELLED,便于其他线程触发unlinkCancelledWaiters逻辑把已取消的节点移除Condition队列。
接下来要进行一个isOnSyncQueue的判断。顺便一提的是Condition本身涉及到两个队列,一个是Condition队列,用来等待被signal,另一个是Sync队列,用来等待获得锁。
final boolean isOnSyncQueue(Node node) {
if (node.waitStatus == Node.CONDITION || node.prev == null)
return false;
if (node.next != null) // If has successor, it must be on queue
return true;
return findNodeFromTail(node);
}
判断是否在Sync队列中的条件是
- 如果状态为Node.CONDITION,则肯定不在Sync队列中
- 如果node.prev未被使用(因为Sync队列是使用prev和next来保存队列节点的引用的),则肯定不在Sync队列中
- 如果node.next被使用,说明肯定在Sync队列中
- 以上几种情况是典型的能明确判断是否在Sync队列的标识。由于节点有可能处于Node.CANCELLED,或者node.next为空,即处于Sync队列的队尾,则没有办法,只好冲Sync队列队尾开始遍历,知道找到节点为止。
由于当前节点在Condition队列中,所以必然不在Sync队列中,从状态上可以分辨出来。因此使用LockSupport.park(this)阻塞当前线程。
private int checkInterruptWhileWaiting(Node node) {
return Thread.interrupted() ?
(transferAfterCancelledWait(node) ? THROW_IE : REINTERRUPT) :
0;
}
final boolean transferAfterCancelledWait(Node node) {
if (compareAndSetWaitStatus(node, Node.CONDITION, 0)) {
enq(node);
return true;
}
while (!isOnSyncQueue(node))
Thread.yield();
return false;
}
当前线程被唤醒分为三种情况:0.正常被唤醒,-1唤醒之前被中断。1.唤醒之后被中断。如果是被中断的话会继续进行transferAfterCancelledWait,这个方法首先会查看当前节点是否还是Node.CONDITION状态,如果被中断就还是这个状态,如果被其他线程signal的话,状态就已经被置为0了,并放入Sync队列中了,下面介绍signal方法的时候可以看到。如果是被中断,则在这里会尝试把状态置为0并放入Sync队列中等待获得锁。如果是被signal,当前线程会检查是不是已经放入Sync队列了,如果不是就自旋,知道确认为止。由于线程被中断的触发发生在被唤醒前后导致后续的处理是继续把中断异常上抛,还是再次恢复中断。
接下来带着之前保存的saveState调用acquireQueued方法,之前介绍过这个方法,独占模式下尝试获取获取sync锁。获取锁失败则阻塞,成功之后继续往下执行。判断作为当前节点有没有后继的Condition节点,再做一次把已取消的节点剔除出Condition队列的操作。最后一步是根据是否中断和中断发生在唤醒前后来执行后续操作。
condition还提供了其他await方法:
- awaitUninterruptibly().不响应中断的await
- awaitNanos(long nanosTimeout) throws InterruptedException.最多await一段时间,单位是纳秒
- awaitUntil(Date deadline) throws InterruptedException.根据给定的时间作为await的最后期限。
- await(long time, TimeUnit unit) throws InterruptedException.有超时时间的await.
所有这些方法都大同小异,只不过在await()方法的基础上做了一些增减,或是去掉了对中断的响应,或是加入了对时间维度的支持。
再来看看如何signal的
private void doSignal(Node first) {
do {
if ( (firstWaiter = first.nextWaiter) == null)
lastWaiter = null;
first.nextWaiter = null;
} while (!transferForSignal(first) &&
(first = firstWaiter) != null);
}
private void doSignalAll(Node first) {
lastWaiter = firstWaiter = null;
do {
Node next = first.nextWaiter;
first.nextWaiter = null;
transferForSignal(first);
first = next;
} while (first != null);
}
final boolean transferForSignal(Node node) {
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
Node p = enq(node);
int ws = p.waitStatus;
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
LockSupport.unpark(node.thread);
return true;
}
仔细观察会发现,signal方法并没有直接unpark await的线程,而是把处于Condition队列中的线程移到Sync队列中,当signal方法执行完之后,lock.unlock()的时候才会由释放独占锁的方式唤醒处于Sync队列中的线程。
signal和signalAll方法的区别在于:signal方法会找到第一个遇到的没有被取消的节点,把他移到Sync队列中。而signalAll方法则会移动所有的Condition队列中的节点。
FutureTask(基于AbstractQueuedSynchronizer)
FutureTask在jdk1.7时进行过一次重写,重写之前的FutureTask是基于AbstractQueuedSynchronizer实现的。重写后摈弃了AbstractQueuedSynchronizer,是为了避免FutureTask在被取消发生的竞争时保留中断状态。重写后的版本会有单独的笔记进行介绍。
FutureTask通常的使用方式是使用线程或线程池来提交一个FutureTask,之后使用Get来阻塞的获得结果。提交任务和获取结果之间是异步的。
现在来看看基于AbstractQueuedSynchronizer的FutureTask是如何实现的。
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
sync = new Sync(callable);
}
public FutureTask(Runnable runnable, V result) {
sync = new Sync(Executors.callable(runnable, result));
}
先从构造函数看起,无论是Callable还是Runnable+Result,共同之处在于,要有返回值。Executors.callable(runnable, result)方法会把Runnable+Result转化成Callable,传给Sync的构造函数。
因为FutureTask实现了RunnableFuture, RunnableFuture继承了Runnable,所以FutureTask实现了run方法会被线程或线程池调用,下面来看一下run方法:
public void run() {
sync.innerRun();
}
FutureTask的run方法实际执行的是sync的innerRun方法。
void innerRun() {
if (!compareAndSetState(READY, RUNNING))//state初始化为READY,这里通过CAS设置为RUNNING,如果失败的话证明futureTask已经被取消,则直接返回
return;
runner = Thread.currentThread();
if (getState() == RUNNING) { //再获取当前线程后再次确认state为RUNNING
//执行callable.call()获得返回值
V result;
try {
result = callable.call();
} catch (Throwable ex) {
setException(ex);//记录异常
return;
}
set(result);//保存返回值
} else {//如果发现state已经改变则释放共享锁
releaseShared(0); // cancel
}
}
当出现任何异常时会通过setException(ex)记录下异常,当得到返回值时会通过set(result)记录下返回值,两个方法实现上是大致相同的,这里只分析一下set(result)方法:
protected void set(V v) {
sync.innerSet(v);
}
void innerSet(V v) {
for (;;) {
int s = getState();//获取状态
if (s == RAN)//如果状态是已完成,则直接返回
return;
if (s == CANCELLED) {//状态是取消,如注释所示,有可能是和取消的线程同时执行了,次时强行释放共享锁,并设置runner为null
// aggressively release to set runner to null,
// in case we are racing with a cancel request
// that will try to interrupt runner
releaseShared(0);
return;
}
if (compareAndSetState(s, RAN)) {//正常情况下设置状态为以完成
result = v;//记录result
releaseShared(0);//释放共享锁
done();//执行扩展方法done
return;
}//如果CAS设置失败,则自旋再次尝试
}
}
另一方面,当提交了FutureTask之后想要获取结果就需要调用get()方法:
public V get() throws InterruptedException, ExecutionException {
return sync.innerGet();
}
V innerGet() throws InterruptedException, ExecutionException {
acquireSharedInterruptibly(0);
if (getState() == CANCELLED)
throw new CancellationException();
if (exception != null)
throw new ExecutionException(exception);
return result;
}
从代码上看就非常简单了,首先获取共享锁,获取过程中接受中断;获取锁后发现状态为取消,则抛出CancellationException;如果有异常说明FutureTask执行失败,抛出ExecutionException异常;如果执行正常,返回结果。
get方法还接收带超时时间的参数,唯一的区别就在于获取共享锁的时候带超时时间。
public V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException {
return sync.innerGet(unit.toNanos(timeout));
}
FutureTask与直接使用线程池最大的不同在于,FutureTask可以取消,下面来看一下取消方法:
public boolean cancel(boolean mayInterruptIfRunning) {
return sync.innerCancel(mayInterruptIfRunning);
}
boolean innerCancel(boolean mayInterruptIfRunning) {
for (;;) {
int s = getState();
if (ranOrCancelled(s))
return false;
if (compareAndSetState(s, CANCELLED))
break;
}
if (mayInterruptIfRunning) {
Thread r = runner;
if (r != null)
r.interrupt();
}
releaseShared(0);
done();
return true;
}
取消方法带一个参数mayInterruptIfRunning,来表示是否可以在任务运行时中断任务。
在innerCancel方法中首先自旋+CAS设置CANCELLED状态,成功之后根据需要中断线程,释放共享锁,最后执行扩展方法done()。这里注意一下返回值代表是否取消成功,如果当前状态是Ran(执行完毕)或CANCELLED的话,会直接返回false,表示取消失败。
最后,FutureTask还附带了runAndReset跑完重置方法,不过由于可见性设置的是protected,所以只会被用在线程池内部用来反复执行任务。