kafka高可用性架构分析
2014-09-14
最近在做自主研发的消息中间件的高可用性策略,这之前调研了一下kafka和RocketMQ是怎么做的,kafka的ha是我见过的ha中最复杂的,我花了一些时间好好研读源码,并画了两示意图,在这里做个笔记,怕自己以后忘了。
话不多说,先上图!
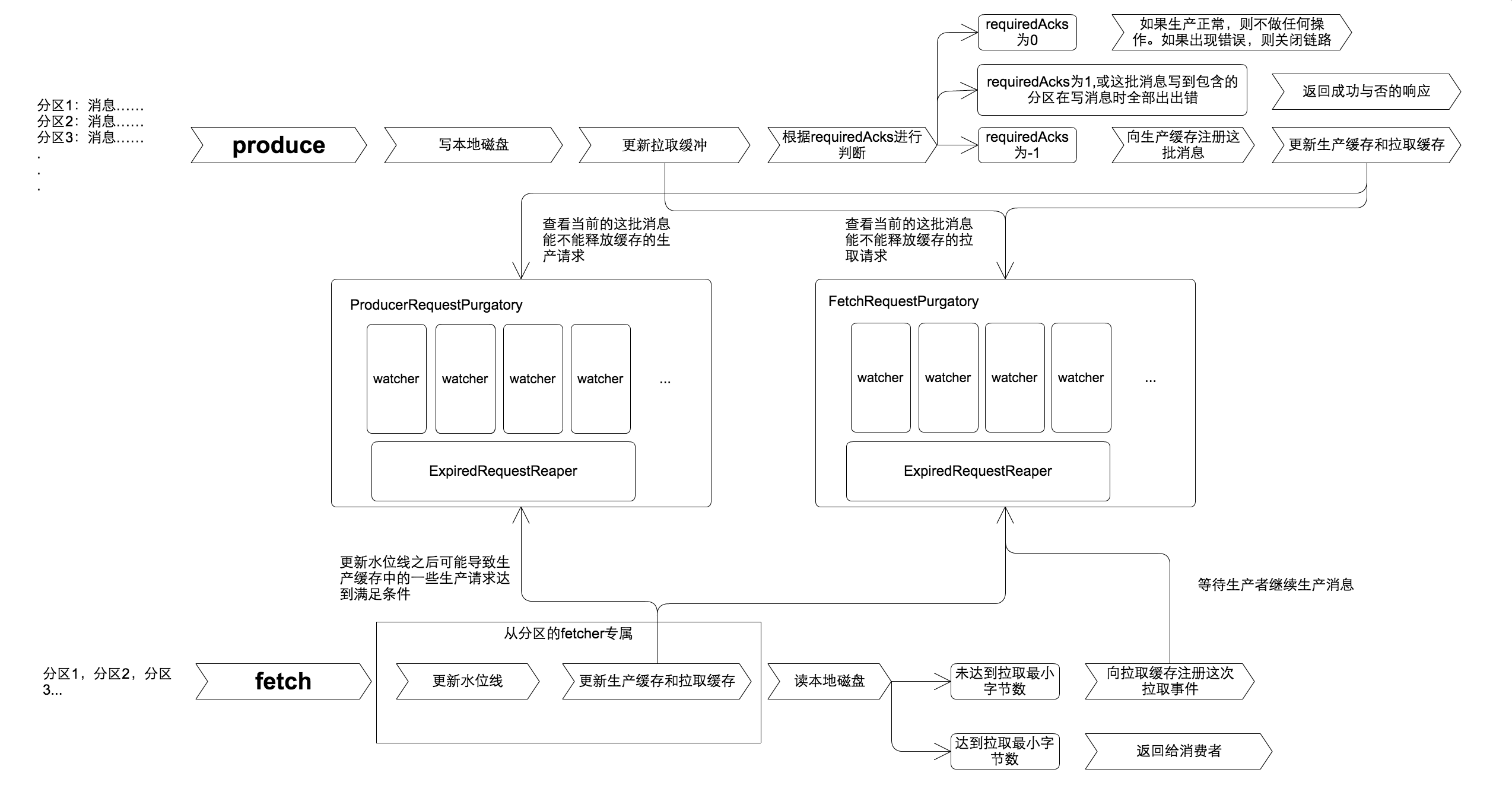
这张图可以描述了HA的purgatory(文中用缓存这个名词来解释)的工作流程,从图中我们可以看出ha的缓存分为生产缓存和拉取缓存两块结构相同的缓存区,分别缓存生产和拉取请求。
为什么会有这两个缓存区?这也是我一开始不理解的地方。经过仔细阅读代码,我有了以下的认识:
当生产者设置了等待从partition的同步选项(requiredAcks为-1)时才会启动生产缓存。因为每一批生产的消息,需要等待所有的处于同步状态的从partition(in-sync)同步成功,在所有从partition上报自己的水位线追上leader partition之前,生产请求会一直保留在生产缓存中,等待直到超时。
拉取请求为什么也需要缓存?因为kafka在消费消息时有一个默认选项,一次拉取最低消费1条消息。那么,如果消费者拉取的时候没有任何新消息生产,则拉取请求会保留到拉取缓存中,等待直到超时。这一定程度上避免了反复拉取一批空消息占用带宽资源的问题,不过也把kafka的ha缓存架构的复杂度提升了一个等级。
kafka的server端主要处理了发送和拉取消息,所有的入口都在kafka.server.KafkaApis这个类里。
代码就不贴出来了,首先发送消息处理的方法为:
def handleProducerRequest(request: RequestChannel.Request) {
...
}
kafka的生产者可以选择批量发送消息,所以在server端接到这批消息时(证明当前server含有leader partition),首先要做的就是把消息写入本地文件。
之后,会第一时间更新拉取缓存。kafka对缓存的处理策略是,任何操作只要有可能会对缓存施加影响,都第一时间进行更新缓存,以尽可能的释放处于等待状态的拉取请求。也就是说有可能等待新消息生产的拉去请求,在这个时候就会带着新消息返回给消费者了。
之后会根据生产者配置的requiredAcks选项分为三种策略,如图所示。只有当requiredAcks为-1会把这批消息的生产请求进行缓存。
缓存之后会迅速对生产缓存和拉取缓存进行检查,kafka不放过任何可以释放缓存中请求的机会。
图片的下半部分是拉取请求的处理,代码中的入口是这个方法:
def handleFetchRequest(request: RequestChannel.Request) {
...
}
因为kafka中,从分区和普通的消费者几乎一致,所有这些fetch请求都会在上面这个方法中进行处理。
fetch请求首先会更新上一次拉取结果的从分区的水位线,因为我们知道什么时候释放生产缓存是根据从分区的水位线是否追上主分区来决定的,所以fetch请求更新完从分区水位线之后会立刻检查是否可以释放生产请求,由于生产请求释放之后会相应地影响被缓存的拉取请求,所以也要检查是否能更新拉去请求。
接下来会读取本地磁盘,按偏移量读出本次能够拉去的消息。
因为kafka有一个可配置项为,每次拉取的最小消息量,默认为至少一笔消息,所以,kafka接下来会根据这个配置项决定是否要创建把拉取请求推入拉取缓存中。
如果拉取请求被推入拉取缓存,那么他回等待新的消息生产,然后才会从缓存中释放,返回给消费者或者从分区。
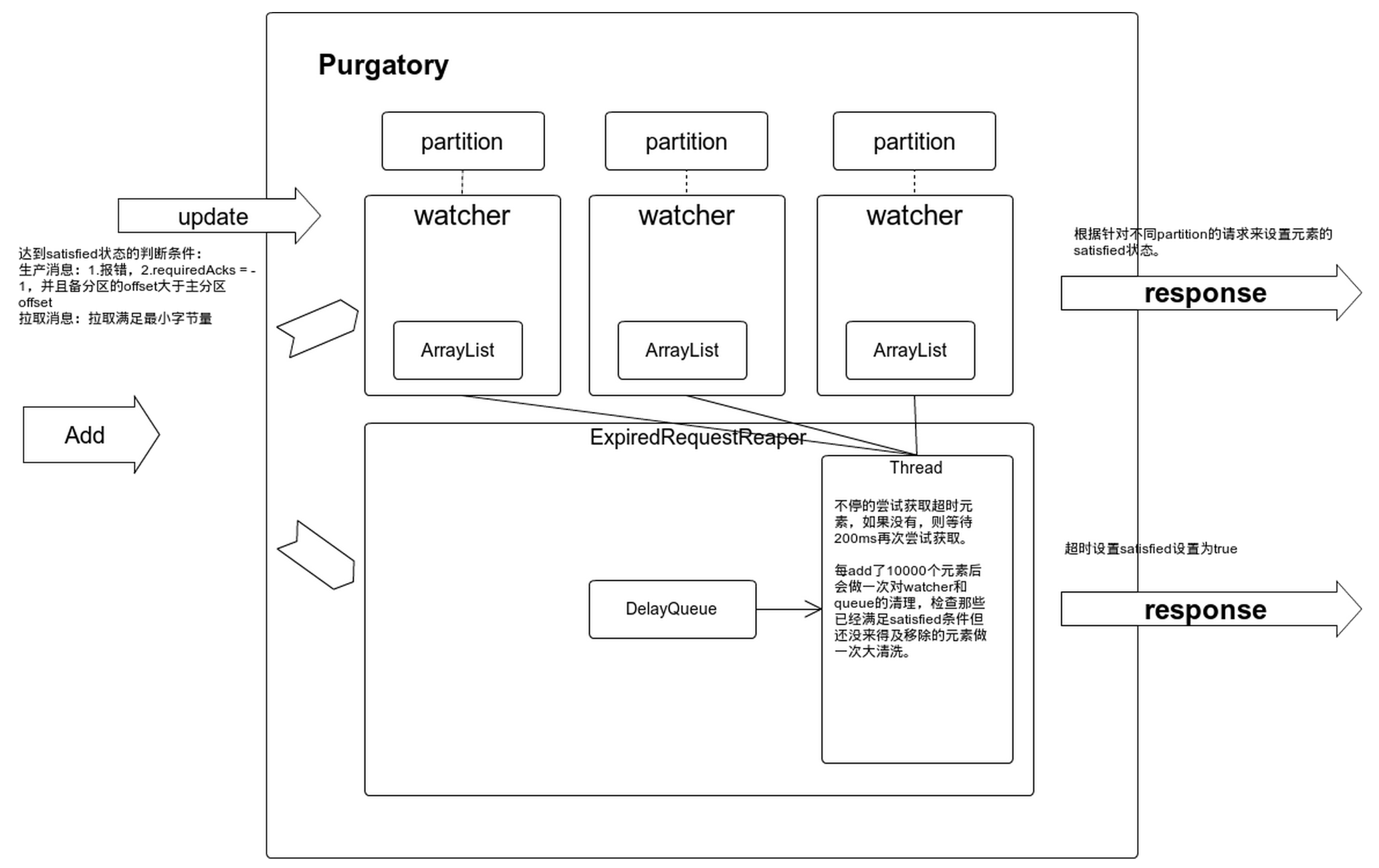
这第二张图展示的是拉取缓存和生产缓存的设计思路。
可以看到缓存从两个维度对请求做了记录,1是partition维度,缓存中为每一个partition创建了一个watcher,watcher中使用ArrayList保存请求,所以任何partition的消息有生产或消费都能找到为这个partition缓存各种请求。2是时间维度。缓存中创建了延迟队列,每一个请求的引用会被推入延迟队列,超时会自动释放掉。
从缓存中释放需要满足一些条件,如图所示,生产请求和拉取请求的满足条件各不相同。只要满足条件,请求就会被标记为satisfied, 会被移除缓存区。
缓存中还额外设有一个检查线程,会定期检查已经达到满足条件,但还没来得及从缓存中移除的请求。要知道这个缓存区是没有边界的,持续不断的请求被放入生产缓存和拉取缓存,但释放不及时会导致内存膨胀过快。所以kafka从各个方面都做了保证第一时间把达到满足条件的请求释放的设计。